2021. 6. 15. 09:00ㆍ빅데이터 잡아라/ADP
안녕하세요~
데이터에듀에서 나온 ADP실기 데이터 분석 전문가의 모의고사가 R로만 짜여저 있어서
ADP실기를 파이썬(python)언어로 보시는 분들을 위해
제가 파이썬 언어로 바꾸면서 코딩을 한 내용을 공유드리고자 합니다.

ADP 실기 모의고사 4회
01. 정형 데이터마이닝 (사용 데이터: weatherAUS)
1) 데이터의 요약값을 보고 NA값이 10,000개 이상인 열을 제외하고 남은 변수 중 NA값이 있는 행을 제거하시오. 그리고AUS 데이터의 Date 변수를 Date형으로 변환하고, 전처리가 완료된 weather AUS데이터를 train(70%), test(30%) 데이터로 분할하시오(set.seed(6789)를 실행한 후 데이터를 분할하시오.)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
path = './모의고사 4회/weatherAUS.csv'
data = pd.read_csv(path)
data.describe().T
data.head()
data.info()
data.isnull().sum()isnull().sum()함수를 통해 각 변수별 결측치 개수를 확인한다.
df = data.copy()
df = df[['Date', 'Location', 'MinTemp', 'MaxTemp', 'Rainfall', 'WindGustDir',
'WindGustSpeed','WindDir3pm', 'WindSpeed9am',
'WindSpeed3pm', 'Humidity9am', 'Humidity3pm', 'Temp9am', 'Temp3pm',
'RainToday', 'RainTomorrow']]
df['Date'] = df['Date'].astype('string')
df['Date']= pd.to_datetime(df['Date'])
date변수를 date형으로 변환한다.
df.info()분석할 변수의 object형을 분석을 위한 변수형으로 전환시켜준다.
df['RainTomorrow']=df['RainTomorrow'].replace({'No':0}).replace({'Yes':1})
df['RainToday']= df['RainToday'].replace({'No':0}).replace({'Yes':1})
df['WindDir3pm'] = pd.get_dummies(df['WindDir3pm'])
df['WindGustDir'] = pd.get_dummies(df['WindDir3pm'])
df['Location'] = pd.get_dummies(df['Location'])
#X와 y를 나눈다.
X= df[df.columns.difference(['RainTomorrow'])]
y=df['RainTomorrow']
#train, test 데이터를 나눈다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=6789)
2) train데이터로 종속변수인 RainTomorrow(다음날의 강수여부)를 예측하는 분류모델을 3개이상 생성하고, test데이터에 대한 예측값을 csv파일로 각각 제출하시오.
3) 생성된 3개의 분류모델에 대해 성과분석을 실시하여 정확도를 비교하여 설명하시오. 또 ROC Curve를 그리고 AUC값을 산출하시오.
#분류모델 3개
#1)decisiontree 2)randomforest 3)knn
#분류모델 평가 함수
def eval(y_test, pred) :
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print('오차행렬')
print(confusion)
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}'.format(accuracy,precision,recall))
#첫번째 분류모델
model1 = DecisionTreeClassifier()
model1.fit(X_train, y_train)
print(model1.score(X_train, y_train))
print(model1.score(X_test, y_test))
y_prredict_1 = model1.predict(X_test)
eval(y_test, y_prredict_1)
y_predict_1 = pd.DataFrame(y_prredict_1)
y_predict_1.rename(columns={0:'predict'},inplace=True)
y_predict_1.to_csv('./predict_model1.csv')첫번째 분류모델의 평가결과이다.
#두번째 분류 모델
model2 = LogisticRegression()
model2.fit(X_train, y_train)
y_prredict_2 = model2.predict(X_test)
eval(y_test, y_prredict_2)두번째 분류모델의 평가 결과는 아래와 같다.
model3 = RandomForestClassifier()
model3.fit(X_train, y_train)
y_prredict_3 = model3.predict(X_test)
eval(y_test, y_prredict_3)세번째 분류모델의 평가는 아래와 같다.
따라서 오차행렬, 정확도, ,정밀도, 재현율을 종합적으로 고려해볼때 RandomForestClassifier()함수가 가장 성능이 좋게 나온것을 알 수 있다.
각 분류모델에 대해 ROC Curve와 AUC는 아래와 같다.
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, roc_auc_score
#첫번째 분류모델 ROC Curve 및 ACU
fpr, tpr, threshold = metrics.roc_curve(y_test, y_prredict_1)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
#두번째 분류모델 ROC Curve 및 ACU
fpr, tpr, threshold = metrics.roc_curve(y_test, y_prredict_2)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
#세번째 분류모델 ROC Curve 및 ACU
fpr, tpr, threshold = metrics.roc_curve(y_test, y_prredict_3)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()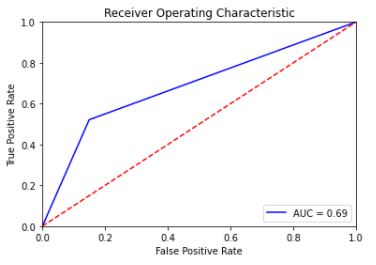
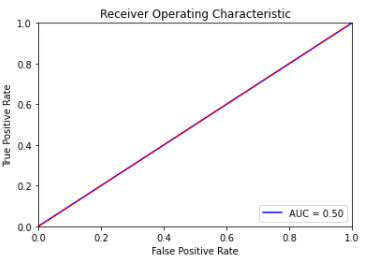
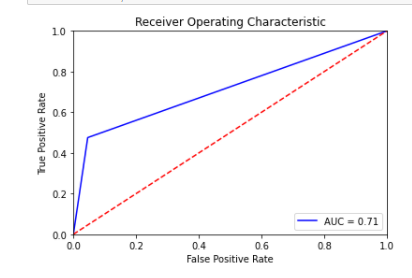
ROC Curve와 AUC의 평가를 보아도, 세번째 모델인 RandomForestClassifier()함수가 가장 성능이 좋다고 볼 수 있다.
'빅데이터 잡아라 > ADP' 카테고리의 다른 글
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 4회 2번 파이썬 코드 (3) | 2021.06.17 |
|---|---|
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 3회 2번 파이썬 코드 (2) | 2021.06.12 |
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 1회 1번 파이썬 코드 (9) | 2021.06.03 |
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 2회 1번 파이썬 코드 (0) | 2021.02.20 |
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 1회 2번 파이썬 코드 (8) | 2021.02.17 |