2021. 6. 17. 09:26ㆍ빅데이터 잡아라/ADP
안녕하세요~
데이터에듀에서 나온 ADP실기 데이터 분석 전문가의 모의고사가 R로만 짜여저 있어서
ADP실기를 파이썬(python)언어로 보시는 분들을 위해
제가 파이썬 언어로 바꾸면서 코딩을 한 내용을 공유드리고자 합니다.

ADP 실기 모의고사 4회
02. 통계분석 (사용 데이터: bike_marketing)

1) pop_density 변수를 factor형 변수로 변환하고, pop_density별 revenues의 평균 차이가 있는지 통계분석을 시행하여 결과를 해석하시오.
import pandas as pd
from scipy import stats
from statsmodels.stats.anova import anova_lm
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.formula.api import ols
import statsmodels.api as sm
import scipy.stats as stats
from scipy.stats import shapiro
import scipy.stats
path = './모의고사 4회/bike_marketing.csv'
data = pd.read_csv(path)
data.head()
#결측치 확인
data.isnull().sum()
#데이터유형 확인
data.info()
기본적인 데이터 형태를 확인해본다.
data['pop_density'] = data['pop_density'].astype('category')
data['revenues'].groupby(data['pop_density']).mean()
sns.boxplot(x="pop_density", y="revenues", data=data)

pop_density유형별 revenues를 boxplot으로 시각화 해서 대략적인 분포를 확인해본다. 각 그룹별 분산과 평균이 비슷해 보인다. 통계분석으로 정확히 확인해보자.
#평균 차이가 있는지 통계분석
#귀물가설은 평균차이가 없다. 대립가설은 평균차이가 있다.
#anova(분산분석)을 사용하여 검증을 하도록한다.
fit = ols(formula='revenues ~ C(pop_density)', data=data).fit()
anova_lm(fit)
#아래와 같이 각 그룹별로 만들어서 여러분석해보는 것도 좋을 듯하다
group1 = data.loc[data['pop_density']=='High',['revenues']]
group2= data.loc[data['pop_density']=='Low',['revenues']]
group3= data.loc[data['pop_density']=='Medium',['revenues']]pop_density별 revenues의 평균차이가 있는지 알아보기 위해서는 일원배치 분산분석을 수행한다. 귀무가설은 평균차이가 없다는 것이며, 대립가설은 평균차이가 있다는 것이다.

유의수준보다 p-value값이 크므로 대립가설을 기각한다. 따라서 통계적으로 pop_density별 revenues의 평균차이는 있다고 보기 힘들다.
2) google_adwords, facebook, twitter, marketing_total, employees가 revenues에 영향을 미치는지 알아보는 회귀분석을 전진 선택법을 사용하여 수행하고 결과를 해석하시오.
model = ols('revenues ~ google_adwords + facebook + twitter + marketing_total + employees' , data=data ).fit()
model.summary2()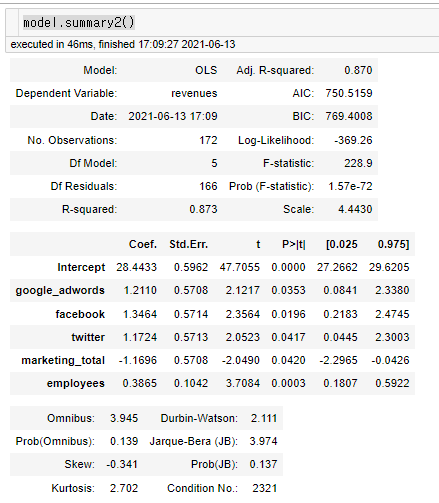
회귀분석을 수행한 결과, p-value가 모두 유의수준 0.05를 넘지 않음으로 모든 변수가 통계적으로 유의하다는 것을 알 수 있다.
variables = data[['google_adwords', 'facebook', 'twitter','marketing_total', 'employees',]].columns.tolist() ## 설명 변수 리스트
y = data['revenues'] ## 반응 변수
selected_variables = [] ## 선택된 변수들
sl_enter = 0.05
sv_per_step = [] ## 각 스텝별로 선택된 변수들
adjusted_r_squared = [] ## 각 스텝별 수정된 결정계수
steps = [] ## 스텝
step = 0
while len(variables) > 0:
remainder = list(set(variables) - set(selected_variables))
pval = pd.Series(index=remainder) ## 변수의 p-value
## 기존에 포함된 변수와 새로운 변수 하나씩 돌아가면서
## 선형 모형을 적합한다.
for col in remainder:
X = data[selected_variables+[col]]
X = sm.add_constant(X)
model = sm.OLS(y,X).fit()
pval[col] = model.pvalues[col]
min_pval = pval.min()
if min_pval < sl_enter: ## 최소 p-value 값이 기준 값보다 작으면 포함
selected_variables.append(pval.idxmin())
step += 1
steps.append(step)
adj_r_squared = sm.OLS(y,sm.add_constant(data[selected_variables])).fit().rsquared_adj
adjusted_r_squared.append(adj_r_squared)
sv_per_step.append(selected_variables.copy())
else:
breakfig = plt.figure(figsize=(10,10))
fig.set_facecolor('white')
font_size = 15
plt.xticks(steps,[f'step {s}\n'+'\n'.join(sv_per_step[i]) for i,s in enumerate(steps)], fontsize=12)
plt.plot(steps,adjusted_r_squared, marker='o')
plt.ylabel('Adjusted R Squared',fontsize=font_size)
plt.grid(True)
plt.show()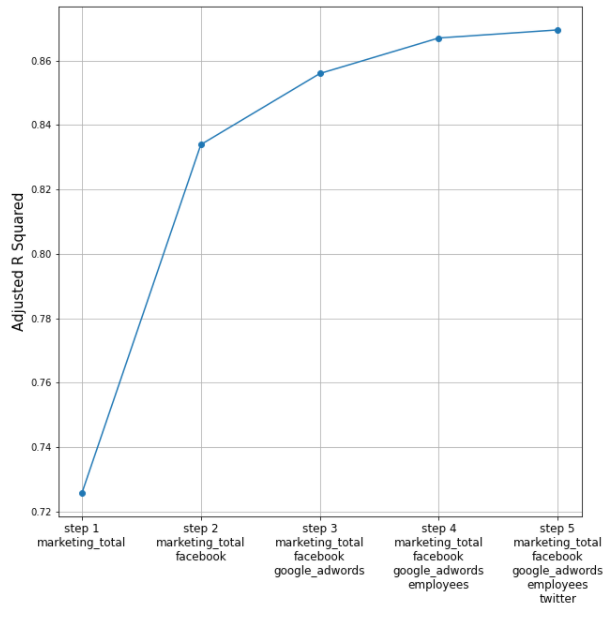
전진선택법을 수행한 결과, 수정계수가 점점 커지는 경향이 보인다. 즉, 어떤 변수를 탈락시키지 않고 모든 변수를 추가한 모델이 가장 성능이 좋다.
즉 최종 선택된 회귀식은 y=28.4433+1.211*google_adwords+1.346*facebook+1.172*twitter-1.169*marketing_total+0.3865*employees이다.
3) 전진선택법을 사용해 변수를 선택한 후 새롭게 생성한 회귀모형에 대한 잔차분석을 수행하고 결과를 해석하시오.
fitted=model.predict(data[['revenues','marketing_total', 'facebook', 'google_adwords', 'employees', 'twitter']])
#잔차
residual = data['revenues']- fitted
#잔차의 세가지 가정 중 정규성 확인
shapiro(residual)

shapiro로 정규성을 확인한 결과, p-value가 유의수준 0.05보다 작으므로 정규성이 있다고 보인다.
#잔차의 등분산성 확인
sr = scipy.stats.zscore(residual)
sns.regplot(fitted, np.sqrt(np.abs(sr)), lowess=True, line_kws={'color': 'red'})
회귀모형을 통해 예측값의 모든 값들의 대해 잔차의 분산이 동일하다는 가정인데, x축은 예측값이고 y축은 잔차의 정규화값이다. 따라서 예측값에 따라 빨간선이 일정하면(수평이면) 등분산성이라고 볼 수 있지만, 모형의 결과는 등분산성이라고 볼 수 없다.
마지막으로 잔차의 독립성을 확인해본다.
잔차의 독립성은 위에서도 언급됬듯이 모형의 summary2()함수 결과에서 확인해볼 수 있다.

더빈왓슨검정은 0이면 잔차들이 양의 자기상관을 갖고, 2이면 자기상관이 없는 독립성을 갖고, 4이면 잔차들이 음의 자기상관을 갖는다고 해석한다. 이 모형은 2.11이므로 잔차의 독립성을 만족한다고 볼 수 있다.
잔차의 세가지 가정 중 등분산성을 만족하지 못해 이 모형은 활용할 수 없다는 결론을 내릴 수 있다.
'빅데이터 잡아라 > ADP' 카테고리의 다른 글
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 4회 1번 파이썬 코드 (1) | 2021.06.15 |
|---|---|
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 3회 2번 파이썬 코드 (2) | 2021.06.12 |
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 1회 1번 파이썬 코드 (9) | 2021.06.03 |
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 2회 1번 파이썬 코드 (0) | 2021.02.20 |
| [데이터에듀]ADP실기 데이터 분석 전문가 모의고사 1회 2번 파이썬 코드 (8) | 2021.02.17 |